But what about causality in machine learning?
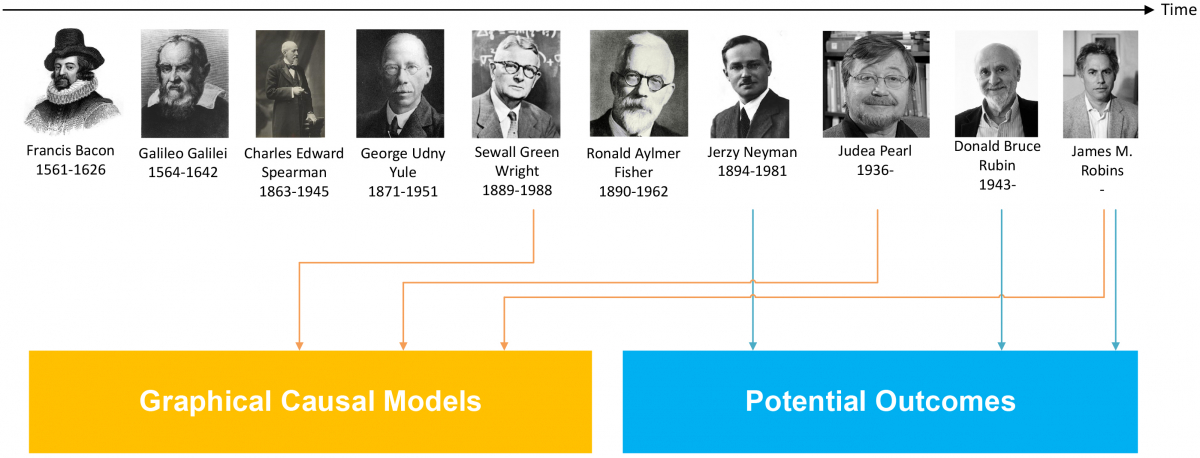
Professor Judea Pearl, a Turing Award recipient, shows that it is possible to include causality in data-driven research through what he calls a structural causal model (SCM). An SCM has three parts, a graphical model made of nodes connected by directed edges, a counterfactual and interventional logic, and a set of structural equations. The first part of the SCM encodes the expert knowledge, while the second part represents the queries that the researcher wants to answer, and the third part provides the semantics for joining the two previous parts with a mathematical language. The required engine for solving the SCM given the data has been refined in the last three decades or so, but it still needs to reach a larger audience, particularly in urban science.
Pearl classifies the inference in causal reasoning within a three-level hierarchy with increasing complexity and analytic power, corresponding to 1. associations, 2. interventions, and 3. counterfactuals. He argues that the capability of a machine learning system to perform causal inference increases from zero in the association level - independent of the amount of data in the experiment – to the ability to reason about the future outcomes of current actions in the association level, to the most complex causal inference analysis capability in the counterfactual level, where the algorithm is able to “reflect” and “imagine” the outcomes that could have obtained had it taken different actions in the past. A machine learning system in a higher level in the hierarchy can perform tasks associated to lower levels, but the opposite is not feasible, which means that machine learning systems framed in lower levels can’t perform inference tasks associated to higher levels.
What’s all this got to do with cities?
The association capability in level one of Pearl’s hierarchy encloses most of the current machine learning applications in prediction, diagnosis, and recognition because they do not consider interventions or counterfactuals. Applications that rely on associations have had a significant impact on urban science and spatial economics during the last couple of decades, and we can’t underestimate them.
However, they don’t provide solid foundations for answering policymaker’s questions such as, what will happen in the future if I take action X now? Or counterfactual questions that the public might have such as “what would the present look like had the policymaker taken action X in the past?” For instance, what would have happened to air pollution in major Colombian cities, if in the 1990s the government had adopted and enforced the European standards for vehicle emissions? We believe that counterfactuals can be a useful approach in the urban planning realm, preventing us from making the same mistakes again. They can help urban planners and local governments reconsider their proposals and think about long-term impacts, and the results of their actions in the future.
We have been collecting and cleaning the input data for our project, and designing a suitable spatio-temporal machine-learning model that can ingest and process multiple variables. As the project evolves, we aim to frame our urban footprint growth model within the causal intervention level from Pearl’s hierarchy. This will enable policymakers and stakeholders to assess “what if” scenarios and answer intervention questions. Some examples include;
- What will happen to the urban footprint if we change the land-use type of a selected area from industrial to residential?
- What will happen to the urban footprint if we list larger areas around water and forests as protected?
- What kind of lands are we going to lose due to urban growth if local governments don’t take action?
By thinking about intervention and counterfactual queries and solving them with “causality-aware” data-driven algorithms, cities will be better equipped to plan and assess urban policies. Including causality in urban contexts is not always feasible, and can be challenging. However, the causality theory combined with new tools and interdisciplinary work will help us to get better insights from data, and to improve our prediction models for planning the transition towards a more sustainable urban future.